Có khả năng hiển thị dữ liệu nhật ký theo thời gian thực có thể giúp xác định cách quản lý ứng dụng và cơ sở hạ tầng được mở rộng. Việc lấy nhật ký từ nhiều nguồn (CDN, bảo mật, phía máy chủ, v.v.) là rất quan trọng để xác định và giải quyết các vấn đề của người dùng cuối. Tuy nhiên, điều này có thể dẫn đến thiết lập cơ sở hạ tầng phức tạp với các mức độ nhu cầu về khả năng hiển thị khác nhau và chi phí thoát cao do khối lượng dữ liệu lớn.
Một cách để đạt được quy trình quan sát hiệu quả, có thể dự đoán và tiết kiệm chi phí là triển khai giải pháp ghép kênh dựa trên đám mây để thu thập và phân tích dữ liệu nhật ký trước khi gửi đến nhóm DevOps có liên quan. Kết hợp với báo cáo nhật ký dựa trên biên DataStream của Akamai , ghép kênh có thể giúp quản lý cách thức và địa điểm truyền nhật ký, cải thiện bảo mật dữ liệu và giảm tổng chi phí.
Hướng dẫn này phác thảo những thách thức kinh doanh của quy trình làm việc về khả năng quan sát, những điều cần biết về tích hợp và di chuyển, đồng thời minh họa kiến trúc tham chiếu ghép kênh đang hoạt động bằng cách sử dụng Linode Kubernetes Engine (LKE) chạy Elastic Stack (ELK) và Vector .
Luồng dữ liệu và quy trình ghép kênh
Dưới đây là các bước cơ bản về cách sử dụng ghép kênh với DataStream trong quy trình làm việc có thể quan sát.
- Máy chủ biên chạy DataStream nhận yêu cầu của khách hàng.
- DataStream xuất dữ liệu nhật ký dưới dạng một luồng duy nhất tới cụm LKE đang chạy giải pháp phần mềm ghép kênh bao gồm ngăn xếp ELK và Vector.
- ELK và Vector thu thập dữ liệu nhật ký. Nhật ký được phân tích, phân tích cú pháp và xuất ra các điểm cuối lưu trữ đối tượng do người dùng xác định.
- Các thùng lưu trữ đối tượng khu vực được sử dụng để lưu trữ dữ liệu nhật ký đã phân tích cú pháp.
Pan upPan downPan leftPan rightZoom inZoom outView large
Vượt qua thử thách
Quản lý nhu cầu quan sát trong toàn nhóm
Sử dụng ghép kênh để chỉ gửi dữ liệu nhật ký đến những người cần nó.
Nhiều tổ chức, đặc biệt là các tổ chức lớn, yêu cầu dữ liệu nhật ký cụ thể phải được gửi đến các nhóm cụ thể trên nhiều vùng địa lý. Nhưng không phải mọi nhóm ở mọi vùng đều cần (hoặc nên có) mọi dữ liệu để đạt được mức độ hiển thị cần thiết của họ. Việc sắp xếp dữ liệu nhật ký chưa được lọc, chưa được phân tích cú pháp không chỉ tốn thời gian và dễ xảy ra lỗi mà còn là rủi ro bảo mật không cần thiết.
Việc giới thiệu phương pháp ghép kênh vào quy trình làm việc có thể quan sát đảm bảo các nhóm DevOps có liên quan nhận được dữ liệu họ cần – và chỉ dữ liệu đó. Điều này không chỉ tăng cường bảo mật dữ liệu mà còn có thể cải thiện hiệu quả và giảm tổng chi phí lưu trữ nhật ký.
Khối lượng dữ liệu lớn
Giảm chi phí bằng cách tránh truyền tải dữ liệu không cần thiết.
Dữ liệu nhật ký là điều cần thiết cho quy trình quan sát hiệu quả. Nhưng nhật ký rất lớn, nhiều và liên tục; luồng dữ liệu nhật ký lớn cần phải đi đâu đó và nếu không được phân tích cú pháp đúng cách trước khi đến đích, có thể dẫn đến chi phí lưu trữ và thoát không cần thiết.
Ghép kênh có thể giúp giảm những chi phí này bằng cách sắp xếp dữ liệu trước thời hạn và chuyển hướng các bản ghi đã phân tích đến các đích cụ thể bằng cách sử dụng “mã định danh” dữ liệu như siêu dữ liệu cụ thể của bản ghi. Không chỉ các bản ghi được gửi đến các nhóm thích hợp mà dung lượng lưu trữ bản ghi tổng thể cũng được giảm bớt bằng cách đảm bảo dữ liệu không cần thiết không được gửi ngay từ đầu.
Duy trì khả năng quan sát với kiến trúc phân tán
Đảm bảo phân phối các loại nhật ký khác nhau đến nơi cần thiết.
Kiến trúc phân tán là một tiêu chuẩn cho các ứng dụng có tính khả dụng cao, khối lượng lớn. Với kiến trúc phân tán đi kèm nhiều vùng, nhiều VPC, nhiều dịch vụ vi mô và nhật ký đi kèm với mỗi thành phần. Ngoài khối lượng dữ liệu lớn, điều này có thể dẫn đến nhu cầu giám sát và khả năng hiển thị phức tạp có thể khác nhau tùy theo từng vùng.
Việc kết hợp ghép kênh dựa trên đám mây với ghi nhật ký biên DataStream cho phép bạn kiểm soát chính xác cách CDN, bảo mật, phía máy chủ và các nhật ký khác được xử lý và phân phối trên cơ sở hạ tầng đa vùng.
Nỗ lực hội nhập và di cư
Giải pháp ghép kênh trong hướng dẫn này không yêu cầu di chuyển bất kỳ phần mềm hoặc dữ liệu quan trọng nào của ứng dụng. Giải pháp này tồn tại dưới dạng đường ống dựa trên đám mây, không phụ thuộc vào vị trí giữa cơ sở hạ tầng phân phối biên và điểm cuối lưu trữ nhật ký của bạn (tức là thùng s3, Google Cloud Storage, v.v.).
Sử dụng ví dụ sau, bạn có thể giảm tổng chi phí thoát dữ liệu bằng cách chuyển kiến trúc ghép kênh đám mây của mình sang Object Storage của Akamai thay vì giải pháp lưu trữ đối tượng của bên thứ ba.
Sơ đồ thiết kế DataStream với Multiplexing
Sơ đồ bên dưới sử dụng cụm LKE có thể mở rộng, một vùng chạy ELK và Vector để thu thập và phân tích một luồng nhật ký duy nhất từ DataStream. Các nhật ký đã phân tích sau đó được gửi đến cơ sở hạ tầng xử lý nhật ký khu vực được tạo thành từ các thùng lưu trữ đối tượng, nơi chúng được xử lý và lưu trữ:
- Yêu cầu được thực hiện. Người dùng cuối gửi yêu cầu ứng dụng.
- Máy chủ biên nhận yêu cầu. Yêu cầu được nhận bởi cơ sở hạ tầng biên của Akamai chạy DataStream. Nếu chưa được lưu vào bộ nhớ đệm trên biên, dữ liệu HTTP cho yêu cầu của người dùng cuối sẽ được chuyển hướng đến cụm SaaS khu vực đang chạy ứng dụng để lấy thông tin do người dùng yêu cầu.Dữ liệu HTTPViệc truyền dữ liệu HTTP không ảnh hưởng và không liên quan đến giải pháp ghép kênh dựa trên đám mây, phân tích nhật ký.
- Nhật ký được gửi đến cơ sở hạ tầng đám mây để ghép kênh. DataStream thu thập và truyền thông tin nhật ký dựa trên yêu cầu của người dùng cuối. Thay vì gửi nhật ký chưa được sắp xếp đến cơ sở hạ tầng xử lý nhật ký khu vực, nhật ký được gửi theo một luồng duy nhất đến cụm LKE khu vực đơn trên Akamai Cloud.
- Nhật ký được phân tích và phân phối. Cụm LKE chạy giải pháp ghép kênh của ELK và Vector sẽ thu thập, xử lý, sắp xếp và truyền nhật ký đã phân tích đến cơ sở hạ tầng xử lý nhật ký cục bộ, khu vực.
- Các thùng khu vực nhận và lưu trữ nhật ký đã phân tích. Cơ sở hạ tầng xử lý nhật ký cục bộ bao gồm các thùng lưu trữ đối tượng và phần mềm thu thập và lưu trữ nhật ký đã phân tích dựa trên các mã định danh dữ liệu được cung cấp trong quá trình phân tích. Các thùng này nằm trong cùng vùng với các cụm SaaS chạy ứng dụng được người dùng cuối truy vấn.
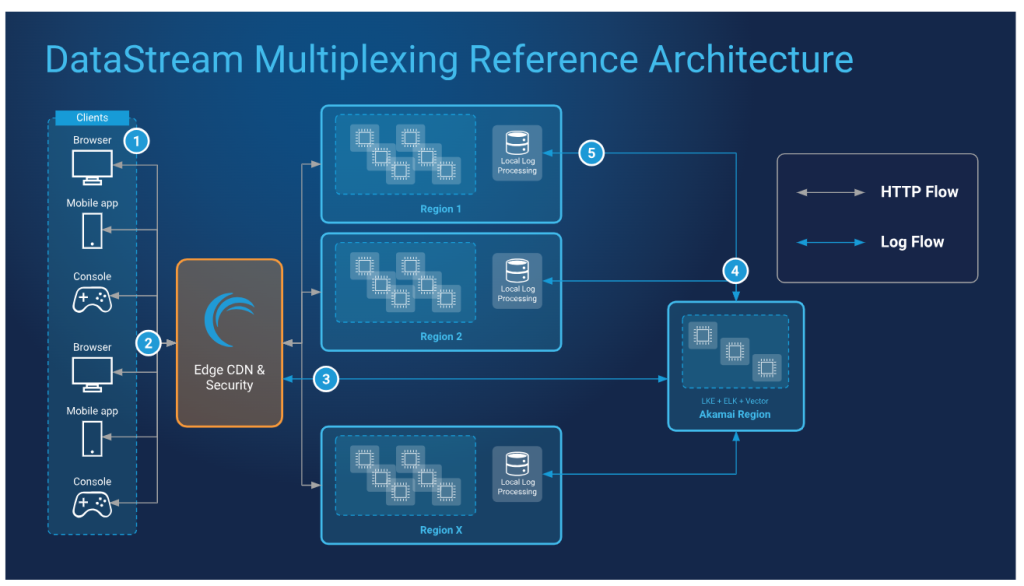
Hệ thống và thành phần
- CDN và Bảo mật biên: Cơ sở hạ tầng biên của Akamai tiếp nhận và định tuyến các yêu cầu và dữ liệu của người dùng cuối.
- DataStream: Dịch vụ báo cáo nhật ký gốc của Akamai và là một trong những giải pháp biên được sử dụng trong trường hợp này. DataStream cung cấp khả năng hiển thị vào việc phân phối lưu lượng bằng cách ghi lại nhật ký hiệu suất và bảo mật, sau đó truyền dữ liệu đó đến các đích do người dùng xác định.
- Cụm SaaS: Cụm các nút trên nhiều vùng chạy chương trình ứng dụng phụ trợ.
- Xử lý nhật ký cục bộ: Thùng lưu trữ đối tượng và phần mềm được sử dụng để thu thập dữ liệu nhật ký đầu ra của cụm LKE chạy giải pháp ghép kênh nhật ký. Nằm trong cùng vùng với cụm SaaS của ứng dụng.
- Các tùy chọn phần mềm xử lý khu vực có thể bao gồm ngăn xếp ELK cục bộ hoặc TrafficPeak.
- LKE: Linode Kubernetes Engine là nền tảng Kubernetes được quản lý của Akamai Cloud Computing. Các cụm Kubernetes được triển khai nhanh chóng và hiệu quả thông qua Cloud Manager, Linode CLI hoặc Linode API.
- ELK: Một ngăn xếp phần mềm bao gồm Elasticsearch, Kibana và Logstash. Ngăn xếp ELK đáng tin cậy và an toàn lấy dữ liệu từ bất kỳ nguồn nào, ở bất kỳ định dạng nào, sau đó tìm kiếm, phân tích và trực quan hóa dữ liệu đó.
- Vector: Phần mềm phân tích dữ liệu được sử dụng để thu thập, chuyển đổi và định tuyến dữ liệu đầu vào/đầu ra, bao gồm thông tin ghi nhật ký.
Nguồn : https://www.linode.com/docs/guides/observability-with-datastream-and-multiplexing/